Train dense layers with tensorflow GradientTape instead of Keras model.fit()

It is interesting to see if it is possible to replace Keras builtin model.fit() method during train with tensorflow GradientTape. I will demonstrate how tf.GradientTape can replace model.fit() with virtually no difference, accurately reproducing the Keras training and gradient calculations. There are many situations where this can come in handy, especially when assessing custom loss functions. This could be a good starting point for developing custom trained neural network models and giving you better understanding how Keras train works.
For this test I will use a small dataset from the Iris example and will compare train results from both methods — model.fit() and tf.GradientTape.
import numpy as np
import datetime
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
import tensorflow as tf
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as pltIris train dataset (limited to 150 samples) was taken from here , data is preprocessed with X_rand.dat containing the four Iris flowers geometric charatctistics and Y_rand.dat containing one-hot type labels, both randomly scrambled. For full description of the Iris dataset see.
X = np.loadtxt('X_rand.dat', dtype=float)
Y = np.loadtxt('Y_rand.dat', dtype=float)
print('X.shape = , Y.shape =', X.shape, Y.shape)Now lets create two Keras models — one to be trained with model.fit() and the other with tf.GradientTape(). For simplicity I will use SGD optimizer with alpha=0.01 and zero momentum. As for a standard multi-class problem I will use softmax activation and loss calculation with Keras categorical-crossentropy.
Also for the initial biases and weights of the Dense layers I use ones initialization — I need this to be able to compare the exact computational results from the two training methods, starting from the same initial condition and removing the uncertainty coming from the default weights initialization in Keras which is using random values. Please however note that initialization with ones weights even as it works Ok for this example should be generally avoided because is causing numerical instabilities.
opt_fit = optimizers.SGD( learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD')
model_fit = Sequential()
model_fit.add(Dense(8, input_dim=4, activation='relu', kernel_initializer='ones', bias_initializer='ones'))
model_fit.add(Dense(3, activation='softmax', kernel_initializer='ones', bias_initializer='ones'))
model_fit.compile(loss='categorical_crossentropy', optimizer=opt_fit, metrics=tf.keras.metrics.CategoricalAccuracy())
opt_tape = optimizers.SGD( learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD')
model_tape = Sequential()
model_tape.add(Dense(8, input_dim=4, activation='relu', kernel_initializer='ones', bias_initializer='ones'))
model_tape.add(Dense(3, activation='softmax', kernel_initializer='ones', bias_initializer='ones'))
model_tape.compile(loss='categorical_crossentropy', optimizer=opt_tape, metrics=tf.keras.metrics.CategoricalAccuracy())Train with model.fit()
Lets first see results from the usual Keras training using model.fit() with the given batch size:
EPOCHS = 200
SAMPLES = 150
BATCH_SIZE = 10
history = model_fit.fit(X, Y, epochs=EPOCHS, batch_size=BATCH_SIZE, verbose=2, shuffle = False)
loss_fit = history.history['loss']
acc_fit = history.history['categorical_accuracy']
On each epoch Keras prints the loss and accuracy. For 200 epochs loss decreases and training accuracy reached 0.9733, quite well for such simple optimization and weights initialization. Loss and accuracy values from the fit() method during training are saved in arrays named loss_fit and acc_fit.
Train with tf.GradientTape
Now, let’s examine how well tf.GradientTape will reproduce the previous training outcome. I will split the data in batches with size batch_size. We need to calculate the loss and accuracy by ourselves. The process involves calculating the average loss and accuracy for each batch, followed by determining the error gradients, and finally updating the model weights using the method outlined below:
loss_tape = []
acc_tape = []
batch_num = (int)(SAMPLES / BATCH_SIZE)
for i in range(EPOCHS):
avg_loss_tape = 0
avg_acc_tape = 0
start = datetime.datetime.now()
for j in range(batch_num):
start_idx=BATCH_SIZE*j
end_idx=BATCH_SIZE*(j+1)
X_batch = X[start_idx:end_idx]
y_batch = Y[start_idx:end_idx]
with tf.GradientTape() as tape:
pred = model_tape(X_batch)
loss = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_batch, pred))
grads = tape.gradient(loss, model_tape.trainable_weights)
opt_tape.apply_gradients(zip(grads, model_tape.trainable_variables))
avg_loss_tape += loss.numpy()
avg_acc_tape += accuracy_score(np.argmax(y_batch,axis=1),np.argmax(pred,axis=1))
elapsed = datetime.datetime.now() - start
avg_loss_tape = avg_loss_tape / batch_num
avg_acc_tape = avg_acc_tape / batch_num
print('Epoch:%d'%i, '\nloss: %.4f' % avg_loss_tape, " - categorical_accuracy: %.4f" % avg_acc_tape, " - %d [ms]" % (elapsed.total_seconds() * 1000))
loss_tape.append(avg_loss_tape)
acc_tape.append(avg_acc_tape)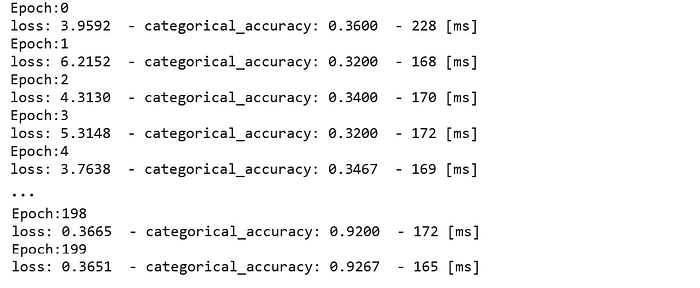
Loss and accuracy from tf.GradientTape() train are recorded for each epoch in loss_tape and acc_tape arrays. Let’s see now how well these results overlaps with the calculated earlier loss_fit and acc_fit:
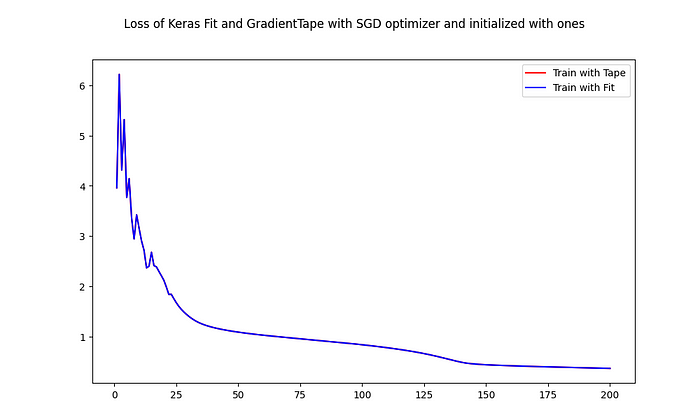
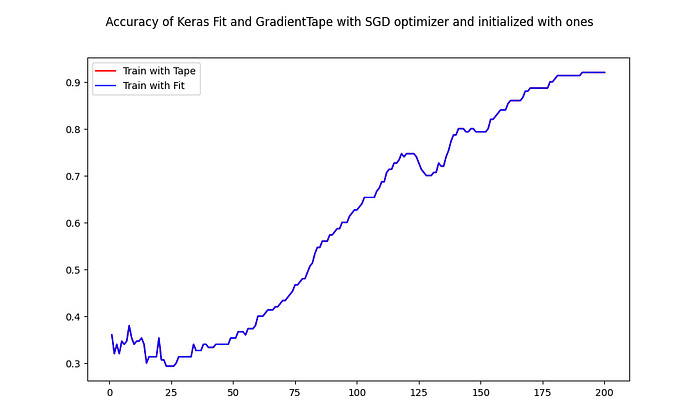
The curves are almost an exact match to one another. The small differences comes from the float calculations precision. This demonstrates that in this test the gradient tape s matching Keras model.fit() training exactly!
Similar results may be obtained and for different batch_size. Also you can remove the ones initialization and would see that loss and accuracy start to differ but both models eventually reaches again similar training results.
Conclusion.
With this test, I have demonstrated that the TensorFlow GradientTape can serve as a precise substitute for the Keras fit() method. Similar results can be obtained and for more complex models which I will show in additional research.
However one thing to note from the results above is that training with error gradients calculation using the GradientTape could be a lot slower than the fit() method (see how this can be further improved here).
The source code for this post is available on Kaggle.
